




Open source is partying hard with the recent release of not one, but two models nearing GPT-4 performance on code-generation and general NLP on various benchmarks. While open source demonstrates its ability to catch up ever faster with the cutting-edge, some may be disenchanted about such benchmarks and feeling slightly less upbeat from the news. Hard to blame when state-of-the-art results can now get outdated before they’re even out.
Speaking of benchmarks, we're excited to finally share with you our collection of model endpoints from all major LLM providers, with dynamic benchmarking across time! We’re iterating on the Model Hub every week so we’d love for you to try out the various endpoints through our unified API and let us know how we can feed the thing. You get a ton of free credits every week, and bonus credits as a small token for reading and supporting the deep dive, so go wild! You can get started by signing up and topping-up with the code “DEEPDIVE”.
Not to sound like that parent who shows pics of their newborn at parties, but if you find it useful it would be super cool if you could give our tweet some love by liking or sharing, or just sharing this post with your friends, that would help a ton! Back to your program now.
Draw me like one of your RPG characters
Diffusion models enable fast and effective text-to-image models but still struggle with complex prompts that involve composing two or more objects with different attributes. Recaption, Plan and Generate (RPG) is a new image generation and editing framework that allows handling such prompts to obtain images with intricate composition of subjects without confusion.
Why would you care? Accurate handling of composition greatly improves many applications of image generation that involve processing content with complex relationships as is the case with architectural constructs or medical imagery for example. And if you've been playing around with diffusion models, chances are you've learned to hate colors by now.
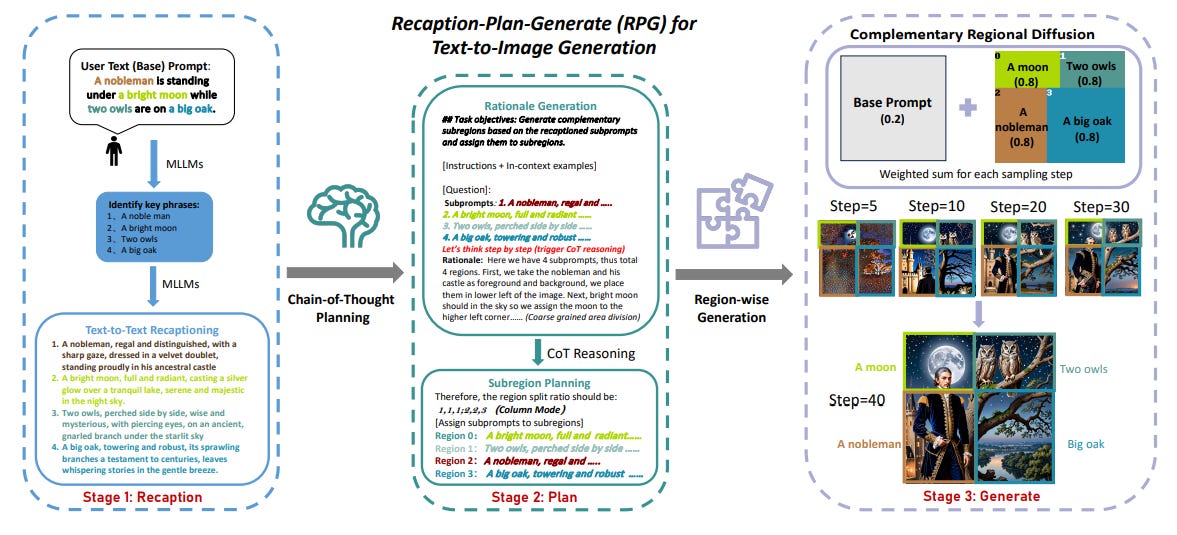
How does it work? Typical approaches to guide generation either involve applying some conditional masking on the image or fine-tuning the model. While this works for the most part, overlapping objects are still difficult to handle and precise fine-tuning can be costly. RPG introduces composability by leveraging multimodal LLMs to transform and adapt the initial prompt. Given a base prompt that includes multiple entities with different attributes and relationships:
The prompt is passed into a multimodal LLM that identifies the key passages corresponding to distinct subjects, divides the prompt into multiple subprompts, one for each passage, and expands each subprompt with more detailed description.
The image is then divided into regions, first by splitting it into different rows and different columns, then, and each subprompt is assigned to a region to generate separate images.
A weighted sum of the base latents (obtained by passing the base prompt into the model) and the concatenated latents (resulting from concatenating the latents of the separate region images) is computed to produce a final image with consistent blending around the edges.
For image editing, the input image is captioned using an image-to-prompt model and the caption is also recaptioned with a multimodal LLM like the base prompt. The same model then compares the subcaptions with the subprompts to check for differences in accuracy, attribute binding, and object relationships. This feedback is then used as input in the subsequent step to plan for the necessary editing instructions. Finally, the contours of the edited regions are in-painted to fix potential issues in transitions.
Check out the repository to get started.
The Lab
Don't skip hardware day - Neural network architectures are often designed for cross-hardware use which typically leads to inefficiencies in large scale deployment set-ups where efficient use of compute resources is required. Hardware-aware architecture design involves tuning the attributes of matrices to optimise general matrix multiplications (GEMM) with the aim to reduce compute inefficiencies at the hardware level. On NVIDIA GPUs, inefficiencies can notably occur when GEMM size does not divide evenly into the size of thread blocks (i.e separate regions used to store output matrices), and when the number of scheduled threads differs from the number of execution units in the GPU. Both scenarios lead to resources wasted on small operations in excess of the GPU's compute capacity, and can be avoided by following a set of guidelines including ensuring the (a) inner and outer GEMM dimension is divisible by 128 bytes, (b) output matrix is divisible into 128 x 256 blocks, and (c) number of blocks that the output matrix is divided into is divisible by the number of execution units. While adjustments may be needed for different hardware and / or novel architectures, these guidelines serve as building blocks for efficient hardware-centric model design that provides higher throughput versus smaller models, while maintaining consistent accuracy.
Scaling sparsely - Parameter Efficient Fine Tuning (PEFT) methods based on unstructured Sparse Fine Tuning (SFT) have recently been explored to tackle the scalability issue of traditional PEFT approaches. SFT involves adding sparse vectors to the model's parameters, then performing joint optimization over the sparse vectors' indices and values. This requires a specialized optimization approach, but current optimization methods remain memory inefficient as they scale with the models' total parameters count. Accumulated Gradient SFT (SFT-AG) is an alternative optimization method for SFTs that scales with the number of parameters which are actually modified during fine-tuning instead. For each sparse vector added to a given model parameter and at each training step, SFT-AG dynamically updates the sparse vector's indices by freezing some of the trainable weights (after resetting them to their pretrained values), while unfreezing some of the frozen weights based on the weights' long-run gradient magnitudes (as estimated by averaging gradients over the previous steps). Extensions to the method (SFT-MA and Quantized SFT) further provide optimization methods for more constrained compute resources and for quantized models, respectively. Notably, the base method outperforms both PEFT and full fine-tuning baselines on most tested configurations.
More cutting-edge research:
Layers smuggler - SwapNet allows executing large neural networks on resource limited edge devices by dividing and swapping network blocks to minimize redundant memory operations. SwapNet achieves notable performance improvements on edge devices while remaining compatible with DNN frameworks.
Sharing views - Researchers recently proposed DaC, a new training method for efficient online rendering of NeRFs. DaC involves dividing input views into clusters based on visual similarity, training separate models on each cluster to improve quality, and combining the models' knowledge through teacher-student distillation.
Memory cues - Memory-Inspired Temporal Prompt Interaction (MITP) is a new image-text classification method that adds temporal prompts to intermediate layers for storing temporal information and facilitating information exchange. MITP achieves competitive results using only 1% of the model's trainable parameters.
The Pulse
AI's Rorschach - Microsoft is patenting a new tool to help explain the decision-making process of its AI vision models by visually representing how different parts of an input image triggers certain parts of the model, enabling quicker identification and correction of errors and biases. This joins the efforts of other technology companies such as Oracle, Intel, and Boeing that have also recently sought patents related to explainable AI.
CheaperAI - OpenAI has announced new versions of their models, including upgraded GPT-4 Turbo and GPT-3.5 Turbo models designed to increase task completion and response accuracy. Pricing for the GPT-3.5 Turbo model has also been reduced by 50% for inputs and 25% for outputs. Moreover, OpenAI plans to soon launch a general availability version of GPT-4 Turbo with vision capabilities.
To AI or not to AI - An expert group of leading specialists from thirty countries will contribute to a significant report evaluating the advantages and potential dangers of advanced AI systems. The International Scientific Report on Advanced AI Safety will compile top scientific research on AI safety to assist policy makers and shape future conversations about secure AI technology development.
And that’s all for this edition, we hope you enjoyed reading through!
The Unify Dev Team.