

The Deep Dive Issue #15
DistriFusion, extreme quantization and LLM buffs.

We're not done hearing about the skirmishes between Google and OpenAI anytime soon, and that's not just on X. After last weeks' video generation showcase, they're both going data-scavenging, forging partnerships with Reddit and Tumblr, respectively. Data sells like gold when profits ride on models, but who knows what the next battleground will be when they're done eating our cookies.
Collaborative Diffusion
Diffusion models are generating increasingly better quality content at the expense of higher latency. Despite efforts to accelerate inference, generation is still handled by only one GPU as tensor parallelism techniques don't work well with diffusion models given the high communication costs from distributed computation. DistriFusion, proposes to use multiple GPUs to speed-up single-image generation without compromising image quality.
Why would you care? - Upcoming image and video generation models may be too heavy to efficiently run on a single device. As access to hardware becomes cheaper, distributed computing may become a necessary tool to deploy such models at scale.
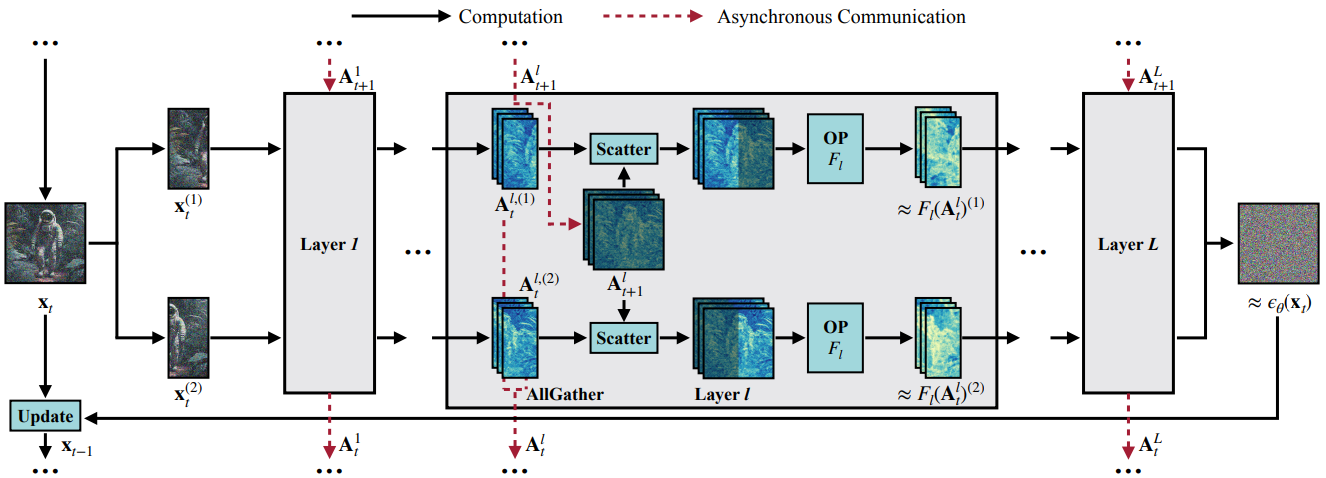
How does it work? - DistriFusion works by dividing the input image into multiple patches and having each device process a single patch independently and in parallel.
When considering a specific layer and device, the input activation patch goes through two main operations:
Scattering: The input activation patch is scattered into the stale activations from the previous step at its corresponding spatial location, and only the portions requiring recomputation need to be updated.
Applying a layer operation: Selective application of the layer operation (linear, convolution, or attention) takes place on the freshly recomputed areas, producing the output for those regions.
Each device handles approximately 1/N of the total computations, allowing for efficient parallelization. Obtaining stale activations from the previous step involves broadcasting activations to all other devices and performing an AllGather operation. With modern GPUs supporting asynchronous communication, this doesn't block ongoing computations.
Additionally, DistriFusion introduces Corrected Asynchronous GroupNorm (CGN) to handle group normalization layers without compromising image quality or introducing significant overhead. CGN computes the group-wise mean of the fresh patch and combines it with the cached local mean and aggregated global mean from the previous step to estimate the global mean more efficiently.
By dividing the image into patches and using synchronous communication solely for the first step, followed by activation reuse for subsequent steps, DistriFusion efficiently utilizes multiple GPUs through its unique inference framework design.
DistriFusion is integrated in HuggingFace's diffusers and can be used to run SDXL as follows:
import torch
from distrifuser.pipelines import DistriSDXLPipeline
from distrifuser.utils import DistriConfig
distri_config = DistriConfig(height=1024, width=1024, warmup_steps=4)
pipeline = DistriSDXLPipeline.from_pretrained(
distri_config=distri_config,
pretrained_model_name_or_path="stabilityai/stable-diffusion-xl-base-1.0"
)
pipeline.prepare()
pipeline.set_progress_bar_config(disable=distri_config.rank != 0)
image = pipeline(
prompt="Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
generator=torch.Generator(device="cuda").manual_seed(233),
).images[0]
if distri_config.rank == 0:
image.save("astronaut.png")
Check out the repository to get started.
The Lab
Make a wish
What's better than generating realistic environments? Generating interactive environments of course. Deepmind researchers released Genie, a new model trained on massive amounts of video data that can generate interactive environments from a single image.
Genie uses a Spatio-Temporal (ST) Transformer architecture, which contains ST blocks with interleaved spatial and temporal attention layers. Spatial attention attends to tokens within each time step, while temporal attention attends across time steps.
Genie consists of three main components, combined in an autoregressive video generation pipeline, namely a:
Latent Action Model (LAM) that learns latent actions in a fully unsupervised manner to achieve controllable video generation.
Video Tokenizer that compresses raw video frames into discrete tokens to reduce dimensionality and enable higher quality video generation.
Dynamics Model that predicts future frames based on past frames and latent actions.
Genie holds promise for various applications such as enabling people to create their own game-like experiences, enhancing human game generation and creativity, and facilitating the training of more capable reinforcement learning agents.
No token left behind
KV caching has become a standard practice in NLP to reduce computational resources. However, empirical observation shows that key details in the input context can get lost upon KV pair eviction, leading to contextual incoherence, hallucinations, and detail loss.
Mixed-precision KV cache (MiKV) is a new compression strategy based on low-precision quantization. It allows retention of some KV pairs at low precision while keeping more important KV pairs at higher precision.
The framework has three main components:
Using low-bit quantization to preserve evicted KV pairs and prevent context loss.
Mitigating the impact of query and key outliers upon quantizaton using dynamic outlier balancing.
Quantizing the importance cache to further achieve memory savings.
Through evaluation on several LLM benchmarks, the researchers showed that MiKV compressed KV cache with minimal performance degradation for compression ratios up to 80%, demonstrating its effectiveness in balancing memory usage and NLP task performance.
More cutting-edge research
Just a little bit - BitNet b1.58 is a new model built using the BitNet architecture, which modifies the traditional neural network linear layer with a "BitLinear'' layer. Weights in this model are represented with 1.58 bits and quantized to -1, 0, or +1 using an `absmean` quantization function, while activations are represented with 8 bits and also scaled to a quantized range per token. This opens new possibilities in terms of efficient deployment of LLMs on resource constrained devices, and better handling of longer sequences.
Second Order Compression - APTQ is a new LLM quantization method that takes into account both the second-order information of each layer's weights and the nonlinear effect of attention outputs on the overall model. It uses the Hessian trace as a sensitivity metric to inform precision reduction while maintaining model performance. Results show that APTQ outperforms other quantization methods, achieving close to full precision with just 4Bits.
Two LoRAs are better than one - A new research presents two learning-free approaches for multi-LoRA composition. LORA SWITCH dynamically adapts the activation of individual LoRAs during the generation process, allowing each LoRA to influence the image generation iteratively. LORA COMPOSITE combines LoRAs simultaneously during the denoising process, incorporating the weight matrices concurrently in the denoising procedure. Findings demonstrate superior output quality, using GPT-4V as a basis for evaluations.
The Pulse
CUDon't - Nvidia has updated its licensing terms to explicitly ban the use of translation layers for running CUDA-based software on other hardware platforms. The move appears to target initiatives like ZLUDA, which both Intel and AMD have participated in, and some Chinese GPU makers who claim to run CUDA code.
Claude the IIIrd - Anthropic has introduced Claude 3, a series of LLMs consisting of Opus, Sonnet, and Haiku variants. According to Anthropic, Opus outperforms GPT-4 and Gemini 1.0 Ultra on multiple benchmarks. Sonnet is competitive with GPT-4, while Haiku is a more cost-effective option. All three models support multimodality, allowing them to interpret both text and image inputs.
Say no to LLM abuse - Cloudflare has introduced a new security measure called Firewall for AI, designed to protect LLMs against various forms of cyberattacks. This includes preventing issues such as misuse of APIs, exposure of sensitive data, and malicious manipulation of LLMs via prompt injection.
And that’s all for this edition, we hope you enjoyed reading through!
The Unify Dev Team.