




Seems like agent systems are all the rage. Every week a new LLM agent repo pops up, boasting better and faster Github issues solving skills (because what better measure of coding skill, right?). We're even starting to see the next frontier of agent-based user interaction with systems capable of controlling and navigating entire operating systems.
Looks like a natural progression when you think about it. First you do away with IDEs, then interfaces altogether. Who knows, maybe we'll soon get wearable agents systems that can run all sorts of tasks with a simple voice command. Legit ones that is.
Taming Agents
Coordinating the cooperation of agent LLMs can be tricky and often results in unpredictable performance. Typical agent frameworks make it easier to experiment but only help streamline the process of building an agent pipeline. AgentScope provides the tools to bring consistency to agentic systems.
Why would you care? - If you think single LLM prompting is already a hit-or-miss exercise, you can imagine how randomness can quickly spill over when trying to orchestrate multiple LLMs. If you're interested in agent stuff, AgentScope could help simplify building consistent agents.
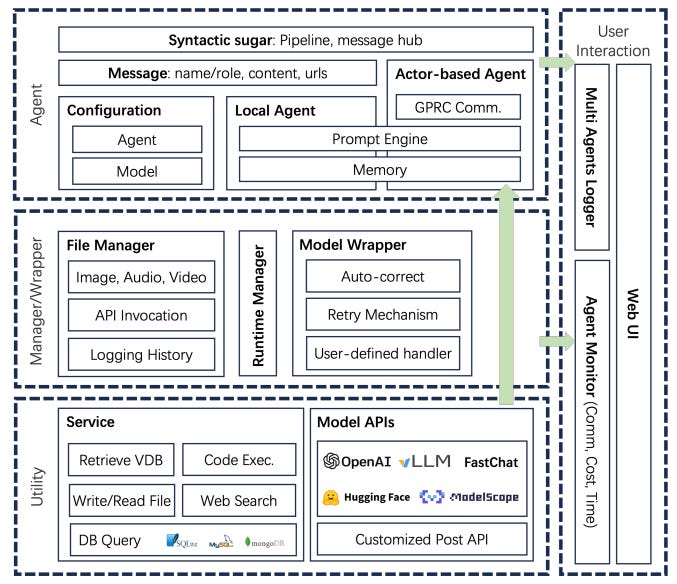
How does it work? - At its core, AgentScope uses a message exchange mechanism for cross-agent communication. This mechanism, along with syntactic tools like pipelines and message hubs, simplifies the process of developing LLM agents. AgentScope also provides built-in resources, including pre-built agents and services like web search and code execution, to further streamline application creation.
Most importantly, AgentScope helps build robust agent systems by incorporating fault tolerance mechanisms at various levels. This includes automatic retries for service accessibility issues, rule-based corrections for formatting errors in LLM responses, and customizable fault handlers for more complex errors. These mechanisms act as fail-safes and allow you to enforce specific behavior without hard-coding the rules from scratch.
AgentScope also offers support for multi-modal data, including generation, storage, transmission, and user interaction. Finally, AgentScope provides an actor-based distributed framework that enables automatic parallel optimization and transitions between local and distributed deployments.
Check out the repository to get started.
The Lab
Multitasking Experts
Increasing the capacity of LLMs to handle more complex tasks typically requires more training. This limitation hinders the ability of MoE-based models to learn from a larger number of expert models as costs scale.
Multi-Head Mixture-of-Experts (MH-MoE) enhances existing MoE models by incorporating a multi-head mechanism. MH-MoE splits each input token into multiple sub-tokens, allowing them to be processed by a diverse set of expert models simultaneously. Each expert model focuses on a specific aspect of the input, providing a more comprehensive understanding of the token's meaning.
After processing, the sub-tokens are seamlessly reintegrated into their original form. This parallel processing and integration of information from various expert models deepen the model's understanding of context while significantly increasing the activation and utilization of expert models.
MH-MoE demonstrated its effectiveness in various tasks, including multilingual language modeling and masked multi-modality modeling, leading to improved performance and a better understanding of complex language concepts.
Snap Chat
Key-Value cache enables faster LLM inference but grows when processing long inputs, leading to increased memory requirements.
To mitigate this, SnapKV compresses KV caches for long inputs without sacrificing accuracy. It first analyzes the attention patterns of the LLM on a small observation window at the end of the input sequence. This window helps identify the most important "keys" from the earlier parts of the input that the model consistently pays attention to during generation.
These important keys, along with their corresponding "values," are then extracted and combined with the observation window to create a new, compressed KV cache. This compressed cache retains the crucial information from the input while significantly reducing memory usage and improving decoding speed.
By reducing the KV cache size, SnapKV offers up to a 3.6x increase in decoding speed and an 8.2x improvement in memory efficiency while maintaining comparable performance to baseline models on various long sequence tasks.
Skip layer day
Running LLMs on lower-end hardware often involves tampering with the model to create a smaller or less flexible version of the model to fit the hardware's capacity.
Instead of tweaking the base model, LayerSkip proposes to speed up inference by efficiently using its layers. During training, LayerSkip randomly removes layers from the model, with a higher dropout rate for later layers, and introduces an early exit loss that trains the model's output layer to understand the representations from earlier layers. This allows the model to make predictions without processing all the layers.
During inference, LayerSkip stops processing after a certain number of layers and makes a prediction based on the output of those layers. LayerSkip then uses the remaining layers to verify and correct the prediction. This approach benefits from shared computations between the draft and verification stages, leading to faster and more accurate inference.
LayerSkip achieves speedups of up to 2.16x on summarization tasks, 1.82x on coding tasks, and 2.0x on semantic parsing tasks, demonstrating its effectiveness in accelerating LLM inference.
The Pulse
Server Cool-down - Snowflake Arctic is a new LLM specifically designed for enterprise needs. It boasts top-tier performance in crucial areas like SQL generation, coding, and instruction following, while being remarkably cost-effective in both training and inference. Arctic's efficiency stems from its unique Dense-MoE Hybrid architecture and a carefully designed training curriculum that prioritizes enterprise-focused skills.
Prompted to Captain - GitHub is releasing Copilot Workspace, a new AI-powered IDE designed to streamline the entire software development process. Starting with a task or issue, Copilot Workspace uses AI agents to generate step-by-step plans, write code, and even run tests, all within a natural language interface. Copilot Workspace is accessible from any device, making it a versatile tool for to optimize coding workflows.
Q's latest gadget - Amazon has launched Amazon Q, a generative AI assistant designed to enhance software development and business operations. Q assists developers by generating code, debugging, testing, and optimizing resources. For businesses, Q connects to internal data sources to answer questions, summarize information, analyze trends, and generate reports.
And that’s all for this edition, we hope you enjoyed reading through!
The Unify Dev Team.