

The Deep Dive Issue #34
GraphRAG, mitigating issues, and coding models

AI continues to improve in relatively short time spans. Yet, the reasoning level, as recently defined by OpenAI’s five levels of AI progress, seems to be an unbreakable glass ceiling. Interestingly, all five levels may not strictly be levels of technological progress. Unlocking actual reasoning could very well enable agents, autonomous systems, and organizational AI, in one fell swoop.
Anything past level two may be more of a societal roadmap as we start to gauge how much work we want to outsource to something we can’t outsmart. A tricky question to answer when the stakes are so high. For now, the species-wide existential crisis can wait until LLMs start to realize that sounding confident doesn’t make them smart.
Mapping Connections
Traditional Retrieval-Augmented Generation (RAG) techniques struggle with complex questions requiring connections between disparate pieces of information or a holistic understanding of themes within large datasets. GraphRAG addresses these limitations by leveraging LLMs to create knowledge graphs from the private dataset
Why would you care? - If you need to retrieve intricate information over a large corpus, simple RAG may not work well enough. Conversely GraphRAG can help improve the accuracy and relevance of your RAG flows in such applications.
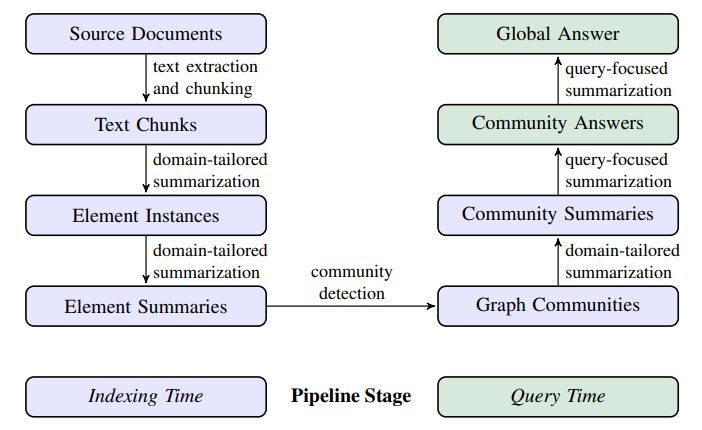
How does it work? - GraphRAG works by combining the power of LLMs with graph machine learning to improve the retrieval and understanding of information from private datasets. The process follows these steps:
LLM-Generated Knowledge Graph: An LLM processes the entire private dataset, identifying entities (people, places, organizations, etc.) and relationships between them. This information is used to construct a knowledge graph, a network representation of the data where entities are nodes and relationships are edges.
Semantic Clustering: The knowledge graph is then used to create semantic clusters, grouping similar entities together based on their relationships. This hierarchical organization allows for pre-summarization of semantic concepts and themes within the dataset.
Query Time Processing: When a user asks a question, both the knowledge graph and semantic clusters are used to enhance the retrieval process. The LLM uses the knowledge graph to identify relevant entities and relationships connected to the query. On the other hand, the semantic clusters provide context and help the LLM understand the broader themes and concepts related to the query.
Answer Generation: Finally, the LLM generates an answer based on the retrieved information, grounding its response in the source material. The knowledge graph and semantic clusters ensure that the answer is comprehensive, accurate, and reflects the relationships and themes present in the dataset.
GraphRAG further provides provenance information for each assertion in the answer, indicating the source documents and specific text segments that support the claim.
Check out the repository to get started.
The Lab
Experts everywhere
Standard transformer models face limitations in scalability due to the linear increase in computational costs as the width of feedforward layers grows.
PEER (Parameter Efficient Expert Retrieval) is a novel layer design that decouples model size from the computational cost by using a large number of relatively small expert networks. Instead of activating all experts for every input token, PEER employs a product key retrieval mechanism to selectively activate a small subset of experts whose parameters are deemed most relevant to the input. This sparse activation scheme significantly reduces the number of parameters actively involved in processing each token, leading to substantial computational savings. The method draws inspiration from the fine-grained MoE scaling law, which suggests that a higher number of smaller experts generally improves model performance.
The PEER layer outperforms traditional dense feedforward networks, coarse-grained MoE models, and Product Key Memory (PKM) layers in language modeling tasks, showcasing superior performance under the same computational constraints.
Artificial quality
The use of synthetic data for training large language models (LLMs) is increasing, but current data generation methods often lead to low-quality data and require significant human effort for curation.
AgentInstruct, is a new system that uses AI agents to automatically create large amounts of diverse and high-quality data. AgentInstruct starts with raw text documents and code as seeds, instead of relying on pre-existing prompts. It then uses three main flows to generate the data: Content Transformation, Seed Instruction Generation, and Instruction Refinement.
Content Transformation analyzes the raw seed and restructures it into a format suitable for creating instructions, like transforming a news article into an argumentative passage. Next, Seed Instruction Generation uses this transformed content to create various task instructions based on a large taxonomy of over 100 subcategories, covering skills like reading comprehension or coding. Finally, Instruction Refinement uses agents to iteratively make the instructions more complex and challenging, ensuring the generated data covers a wide range of difficulties.
AgentInstruct was used to generates a large dataset of 25 million instruction-response pairs to train Orca-3. Compared to other models of similar size, Orca-3 shows significant improvements in various benchmarks, indicating the potential for AgentInstruct in generating high quality synthetic data.
Sanity Meter
LLMs sometimes generate incorrect information, even when correct information is present in the provided context. This phenomenon, called contextual hallucination, poses a significant challenge in tasks like summarization and question answering.
Lookback Lens is a new method that aims to mitigate contextual hallucinations. This method is based on the observation that when hallucinating, an LLM tends to pay less attention to the provided context and more attention to the text it's generating itself.
Lookback Lens examines the attention mechanism of the LLM, which reveals where the model is focusing during text generation. It specifically calculates the ratio of attention given to the context compared to the newly generated text for each attention head at each step (lookback ratio). These ratios from all attention heads are then combined into a single vector representing the generated text segment. Finally, a simple linear classifier is trained on the vectors to predict if a generated text segment is consistent with the provided context or if it's a hallucination.
Lookback Lens successfully detects and helps mitigate contextual hallucinations, sometimes surpassing more complex methods.
The Pulse
Coding Snake - Mistral announced the release of Codestral Mamba, a new, open-source language model designed for efficient code understanding and generation. Codestral Mamba leverages the new Mamba architecture to offer linear time inference and the ability to handle very large sequences, making it particularly well-suited for coding applications.
Sanbox Agents - Claude Engineer just got an update with it’s 2.0 version with the addition of code editor and code execution agents, enabling dynamic editing of files. These agents work in batches, intelligently adjusting to file complexity. The code execution agent can run code, check for issues, and even start and end processes. For safety, all code is run in predefined virtual environments to execute any code securely.
Byte-sized - OpenAI released a new method for improving the legibility of language model outputs. Inspired by the prover-verifier game concept, they trained a strong language model to produce solutions that can be easily verified by a weaker language model. This training not only improved the accuracy of the solutions but also made them easier for humans to understand and assess.
And that’s all for this edition, we hope you enjoyed reading through!
The Unify dev team.