

The Deep Dive Issue #5
S-LoRA, efficient training, and specialised chips

We're almost reaching 2023's end, and with so many things that took place in AI this year, it's the perfect chance not to take a retrospective look at everything. No time to look back when every week has months' worth of progress so let’s keep rolling!
LoRAs unleashed
Fine-tuning pre-trained models has demonstrated superior performance, but serving at scale remains an issue despite several parameter efficient fine tuning methods (PEFT) that make the training process more efficient. S-LoRA extends one such a PEFT method, namely LoRA, to massively serve fine-tuned models at scale.
Why would you care?: S-LoRA can boost throughput by 30x compared to using HF's built-in PEFT, and even 4x compared to the SOTA vLLM, making a robust choice to serve at scale, especially with LLMs.
How does it work? Low-Rank Adaptation (LoRA) is a fine-tuning technique that freezes a pre-trained model's weights then adds and only updates trainable low-rank matrices consisting of a small number of parameters (adapter weights) to generate LoRA weights that can be merged with the base model's for no inference overhead.
While LoRA enables fast inference, it isn't efficient for concurrent serving of multiple adapters as it involves increased latency as well as memory and resource management issues. To tackle said issues, S-LoRA provides:
Optimised Batching: The original LoRA approach merges adapter weights into the base model, but this leads to multiple weight copies and doesn't scale efficiently. On top of applying batching to the base model, S-LoRA also proposes separately batching the LoRA computations on-the-fly using custom CUDA kernels to mitigate the computation overhead. Batching efficiency is further enhanced by clustering requests that use the same adapter which reduces the number of active adapters in any running batch.
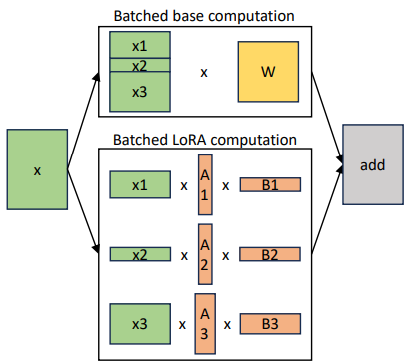
Separated batched computation for the base model and LoRA computation.

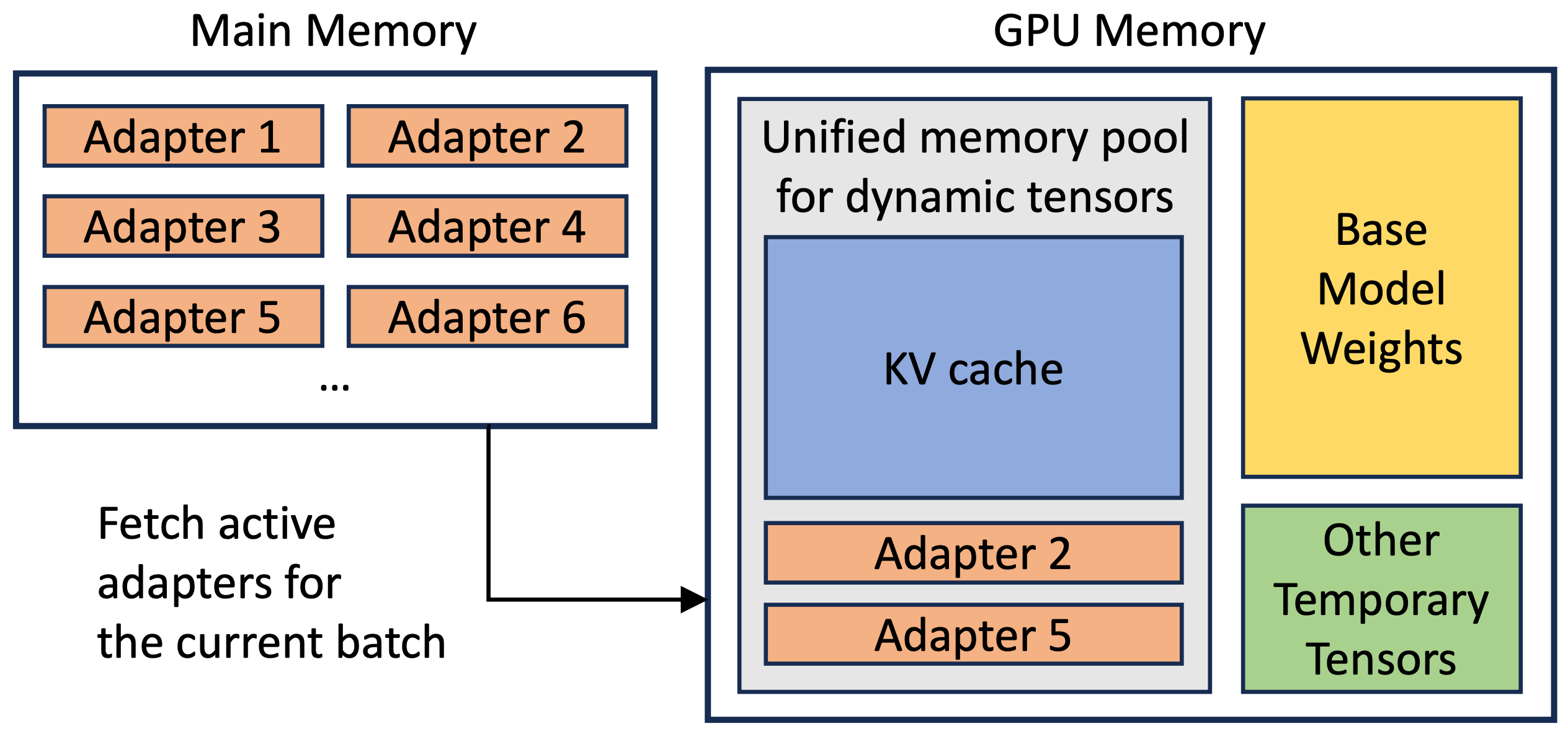
Scalable Memory Management: To support many adapters, S-LoRA stores them in the main memory for dynamic loading. This generates memory fragmentation as both the adapters and token cache vary in size, and increases latency from dynamic loading / unloading of adapters. S-LoRa stores both adapters (Dimension R x H) and cache (Dimension S x H) in a unified memory pool divided into equal-sized sections (pages) of size H used as a common dimension to reduce fragmentation. Further, latency is reduced by anticipating the next batch's required adapters based on a waiting queue and prefetch them ahead of time.

Storing cache and adapters in a unified paged memory pool.

Efficient Resource Usage: Leveraging multiple GPUs requires the use of parallelisation strategies. S-LoRA employs a unique strategy that accommodates the introduction of new weight and matrix multiplications from LoRA. The strategy aligns the partitioning of inputs and outputs of the added LoRA computation with the base model's partitioning to reduce costs by avoiding unnecessary communication.
To get started using S-LoRA, check out the repository.
The Lab
You only train once - Currently, methods for pruning neural network architectures require a lot of manual work and domain knowledge to make optimal design choices. Further, because pruning is also typically introduced on a trained model, it generally calls for further fine-tuning to recover some of the lost accuracy. To address these issues, researchers from Microsoft have developed OTOv3, a novel tool that extends previous versions by providing automatic network pruning during training time. OTOv3 first establishes the search space by analysing the relationships among the operators in the network and their dependency graph. The search space consists of the smallest indivisible network components that can't be removed without affecting the network's overall functioning. With the search space thus defined automatically, optimization algorithms are used to identify redundant network components and train the important ones for high performance, before constructing sub-networks by removing the redundant structures. Because the whole process is automated, OTOv3 could help make model compression more accessible and efficient.
Training set-ups, guess-work no more - Training tools and techniques have grown exponentially. While this provides more options, it also makes it more difficult to find the most optimal configurations. Enters, vTrain a profiling-driven simulator that wants to address this issue and allow users to find the most cost effective and compute efficient configuration for training large language models (LLMs) by estimating the expected training time. The simulator begins by ingesting various relevant metadata (such as target LLM or number of GPUs). It then constructs a high-level execution graph to represent the various operators to execute for a given configuration, and uses this graph to determine which low-level CUDA kernels to execute for each operator involved while measuring the latency incurred in executing each kernel. Finally, vTrain translates the high level operators graph into a low level tasks graph based on the operator-kernel pairings, before simulating single iteration training time. This novel approach provides a systematic system for building efficient training pipelines without the need to run expensive tests on various set-ups.
More cutting-edge research:
ACPO: AI-Enabled Compiler-Driven Program Optimization: - Introduces a novel framework to provide LLVM with simple and comprehensive tools to benefit from employing ML models for different optimization passes.
Data-Efficient Multimodal Fusion on a Single GPU - Proposes a multimodal augmentation scheme that operates at the latent spaces level or pre-trained encoders to achieve competitive training and inference performance.
Accelerator-driven Data Arrangement to Minimise Transformers Run-time on Multi-core Architectures - Suggests a novel memory arrangement strategy, kernel size, to minimise off-chip data access and effectively mitigate memory bandwidth bottle-necks when using hardware accelerators.
The Pulse
The Big Bet - Intel recently launched its Meteor Lake PC CPUs, featuring a built-in AI accelerator for improving AI performance, power efficiency, and graphics. The new chip delivers 1.7 times the performance in generative AI and is 2.5 times as power efficient as the last-generation. To back this up, Intel demonstrated running LLaMa2-7B on a Meteor Lake system using the CPU, GPU, and AI hardware, cementing the potential for mass-consumer access to local AI assistants. The Meteor Lake architecture includes an Intel Arc GPU, and an integrated neural processing unit (NPU), claiming 34 trillion operations per second (34 TOPS). Although this is behind Qualcomm and AMD's latest offerings, Intel is working on ways to leverage the contributions of developers and strategic partnerships to build a strong ecosystem of applications built around their technology, potentially giving them an edge in this nascent market.
Transformers, from the comfort of your chip - Etched has developed a transformer supercomputer using their Sohu chip, which they claim to offer 140 times the performance per dollar of traditional GPUs. The supercomputer, which etches transformer architecture into silicon chips, boasts impressive capabilities when combined with NVIDIA's 8xA100, 8xH100, and 8xSohu, achieving unprecedented performance metrics in Tokens Per Second (TPS), while its multicast speculative decoding allows real-time content generation, enabling dynamic and responsive applications. Etched's chip could open the door for running trillion-parameter models with unparalleled efficiency.The company plans to bring the Sohu chip to market in Q3 2024, targeting major cloud providers.
And that’s all for this year’s last edition. We hope you enjoyed reading The Deep Dive and that you’ll enjoy learning about next year’s promising innovations with us even more! We wish you a great end of the year and look forward to seeing you next week!
The Unify Dev Team.