




It hasn't been two weeks into the new year that we're already witnessing dramatic changes in the industry, with new exciting updates to AI tools and new companies emerging with innovative solutions. We're also excited to be releasing the first version of our Hub, more details to come soon!
Divide and Infer
Data privacy and cost reduction are fueling the interest for local LLM deployment, but the memory requirement mismatch between consumer hardware and modern LLM architectures remains an issue. PowerInfer exploits insights from inherent patterns in LLM inference to propose an efficient engine to run LLMs on personal computers with a single consumer-grade GPU.
Why would you care? PowerInfer achieves up to 11.69× faster LLM inference compared to the SOTA llama.cpp, without compromising accuracy. The engine is also compatible with various popular LLMs like LLaMA and Falcon, with planned support for more models.
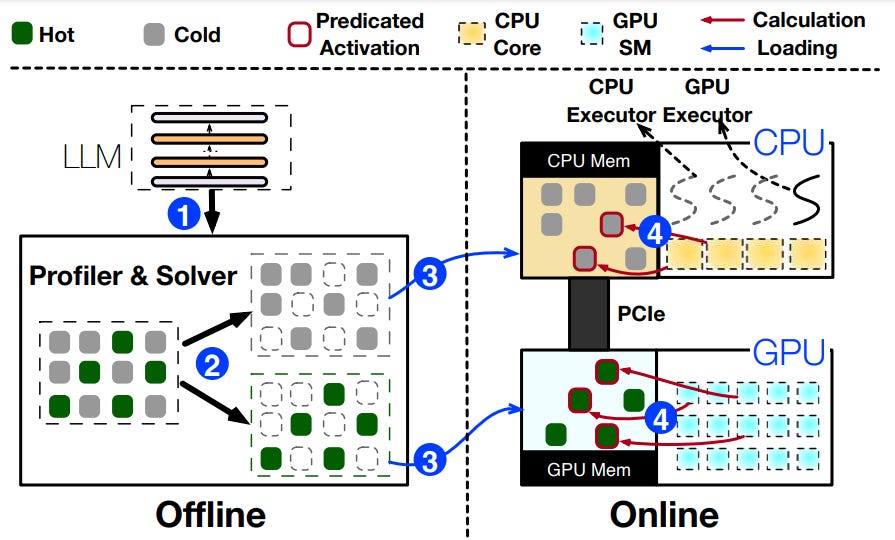
How does it work? PowerInfer is designed to exploit the fact that LLM inference tends to exhibit high locality where a small number of neurons are consistently activated across inputs, while the majority of neurons are only activated for specific inputs. It uses this insight to split the inference process between the GPU and CPU.
Like an air of Deja Vu: While the activation of specific neurons cannot be predetermined before inference, previous research has shown that it is possible to predict neuron activations a few layers in advance within the ongoing iteration. DejaVu achieves at least 93% accuracy rate in predicting neuron activation using MLP-based predictors, and accelerates LLM inference by selectively processing only those neurons that are predicted to be activated while bypassing the inactivated ones.
Previous methods attempt to exploit this activation sparsity but are ill-suited to local deployment. For e.g DejaVu heavily relies on frequent transfer of activated neurons from CPU to GPU during runtime, which is slow on consumer-grade hardware. It also uses an MLP-based predictor to predict neuron activation but the predictors need to be stored in GPU memory for fast access which restricts the already limited space needed for the LLM's parameter. PowerInfer addresses the first issue by using NVIDIA Unified Memory (UM) to efficiently fetch parameters from CPU memory and allow for faster computation of activated neurons on CPU. PowerInfer also relies on non-fixed-size predictors that adjust the size of the hidden layer based on the sparsity and skewness of the LLM layers, reducing (increasing) the predictor size for layers with high (low) skewness. This allows PowerInfer to limit predictor parameters to 10% of the total LLM parameters while maintaining accuracy.
The system consists of two major components:
An offline LLM profiler and Policy Solver. The profiler first collects runtime inference data for each neuron by deploying the LLM on diverse datasets and inserting a monitoring kernel after each Transformer layer block which tracks activation counts for each neuron. Once all requests are processed, the profiler retrieves the activation data and passes it to a policy solver which assigns frequently activated (hot) neurons to the GPU and others (cold) neurons to the CPU based on a given policy. The policy is generated by a solver that considers factors such as activation frequency, communication overhead, and processing unit capacities. For each neuron, it creates an impact metric (defined by its activation frequency obtained during profiling) that measures the neuron's contribution to the LLM’s overall inference outcome. Finally, the policy solver constructs an integer linear programming model to determine the optimal neuron placement in the GPU based on an objective function that aims to maximise the total impact of all neurons. When determining the optimal allocation, the solver also needs to minimise the communication overhead between processing units and involves balancing their memory capacities. The objective function and constraints are then input into an integer linear programming framework to find the optimal solution that maximises the function.
An online Inference Engine. The engine first loads the neurons based on the assignments determined by the allocation policy. During inference, a global queue in the CPU memory stores a computationally directed acyclic graph (DAG) with each node representing a computational LLM inference operator. The engine creates two threads (one on CPU and one GPU) that pull operators from the queue, check for dependencies, assign the operators to the appropriate processing unit, ensure GPU computations are complete before the CPU processes its operators, and merges the CPU processing results to the GPU results. Notably, the operators used during inference are said to be Neuron-Aware as they directly compute the activated neurons and their weights without needing to perform static compilation nor dynamic conversion to dense formats (which introduces performance overhead) as is the case for current sparse matrix multiplication tools. This is advantageous for small-batch-size processing on GPU as it avoids unnecessary computations and memory operations, and for CPU computations in general as it limits the need for parallelism and divides neurons into smaller batches for concurrent processing.
Check out the repo to get started using it.
The Lab
Learning shapes you - Traditional artificial neural networks (ANNs) architectures are typically fixed which can limit their representation ability. A new neural network called X-Net addresses this by dynamically selecting appropriate activation functions and adjusting the network structure in real time based gradient information during training. X-Net reduces computational costs and improves representation power, expected to achieve up to 0.985 R² by using only 3% of the baseline parameters on average. Like an ANN, X-Net includes both forward propagation and backpropagation. However, unlike an ANN, X-Net's backpropagation mechanism alternates between updating the parameters and activation function of the network nodes. This is done by first initialising a random tree-like network structure and then using forward propagation to obtain a predicted value. The algorithm then takes partial derivatives with respect to the constants and node outputs, and updates both constants and activation function (based on a library of 12 functions) alternately until a predetermined number of iterations or level of accuracy is reached. The authors introduce a set of rules and restrictions when updating the activation functions to ensure efficient propagation and avoid computation errors. They also account for the possibility of getting stuck in local optimum by changing the activation function of an arbitrary node when the loss function doesn't change for a time. Finally, the step size used in the training process is also designed to adapt to the incremental change in loss values such that the network uses a smaller (higher) step when the loss drastically (barely) changes. Because of its dynamic nature, the methodology has a wide range of applications across disciplines and can help discover new efficient architectures.
Edgy Spikes - Spiker+ is a framework for creating efficient Spiking Neural Network (SNN) accelerators on Field Programmable Gate Arrays (FPGAs) for edge inference. Spiker+ offers a Python-based interface to develop complex neural network accelerators with minimal code and shows competitive performance in terms of resource allocation, power consumption, and latency compared to SOTA SNN accelerators. On top of a customisable interface, the Spiker+ architecture is designed to be generic and adaptable. It consists of three hierarchical levels of Control Units (CUs). The network CU synchronises components within the network, coordinating the temporal evolution of neurons in different layers during an inference process. The layer CUs orchestrate the update of neurons based on input spikes, delivering spikes to neurons in a parallel and sequential manner. And the neuron CU updates the membrane potential in each neuron, with neuron models translated into dedicated hardware implementations and taking advantage of the binary nature of spikes to simplify the multiplication operations. Spiker+ further leverages the accelerators' integration of memory and computation to optimise performance, using internal look-up tables to process low-memory-requirement items such as neuron parameters, and processing higher-memory-requirement items like synaptic weights by accessing discrete units of SRAM positioned near computing elements (Block RAM - BRAM). All neurons access their respective weights in parallel, leveraging on-board BRAM parallelism. Spiker+ is the first SNNs accelerator tested on the Spiking Heidelberg Dataset (SHD), a publicly available dataset of neuronal spiking activity recordings that is unique in its combination of neural activity data, making Spiker+ an viable solution to deploy configurable and tunable SNN architectures in resource and power-constrained edge applications.
More cutting-edge research:
Incremental FastPitch: Chunk-based High Quality Text to Speech - Researchers from NVIDIA introduced Incremental FastPitch in a new paper, a novel variant of FastPitch that enables high-quality incremental speech synthesis with low latency by introducing chunk-based Fast-Fourier-Transform (FFT) blocks, receptive-field constrained chunk attention masks, and fixed size past model states, to improve the initial model's parallelism.
Fast Inference Through The Reuse Of Attention Maps In Diffusion Models - Researchers from the University of Warwick, Samsung AI Center, and Cornell University, proposed a new approach to improve the efficiency of text-to-image diffusion models that doesn't rely on increasing sample step sizes as is common in practice. The authors suggest reusing attention maps, based on a custom algorithm, to avoid expensive re-computing.
LLM Augmented LLMs: Expanding Capabilities Through Composition - Google and DeepMind recently dropped CALM, a new algorithm which allows composing existing LLMs with smaller, task-specific models. CALM uses cross-attention to combine the representations of the models, allowing for new capabilities without altering the existing model weights. Notably, they demonstrate various use cases, including augmenting PaLM2-S with a smaller model trained on low-resource languages to achieve improved performance (comparable to fully fine-tuned models) on translation and arithmetic tasks, or augmenting the same model with another code-specific model to improve code generation and explanation tasks.
The Pulse
HuggingFast - HuggingFace just released a new update to their diffusers library which introduces various features and notably provides up to 3x speed-up on text-to-image diffusion using various PyTorch-native optimizations such as running with bfloat16 precision, scaled dot product attention, torch.compile, and dynamic int8 quantization. The improvements can be introduced with a few lines of code as outlined in the official repository.
Go bigger, go faster - Researchers at the Institute of Computing Technology at the Chinese Academy of Sciences have proposed an architecture called "Big Chip" to address the current limitations of lithography and chiplets, as they describe in their paper. The Big Chip implementation known as "Zhejiang" uses 16 chiplets but has the ability to scale up to 100 chiplets in a single discrete device. The architecture aims to minimise latency and optimise memory usage by utilising a hierarchical interconnect system, advanced packaging technology, and careful design of communication networks and memory resources. While the approach is reminiscent of Cerebras' wafer architecture, Big Chip could offer new insight into building this kind of large-sized architectures.
Articulating a vision - Intel has formed a new independent company called Articul8, which will focus on providing generative AI software solutions for organisations. The new company aims to address concerns about privacy, security, and cost sustainability in AI work, and is targeting organisations with high levels of security requirements and specialised domain knowledge. The company's software can accommodate other infrastructures, it primarily relies on Intel Xeon Scalable processors and Intel Gaudi accelerators. As such, the new company could be a way for Intel to stimulate demand for its AI hardware and to compete with rivals Nvidia and AMD, among others, in the fast-expanding AI ecosystem.
And that’s all for this edition, we hope you enjoyed reading through!
The Unify Dev Team