




Thousands of researchers agree in a 10% likelihood machines will outperform humans in every possible task within the next 3 years. Ignoring the spike of existential angst for a sec, it's fascinating to think about what future will be built around this societal shift where value creation is mostly driven by compute power and efficiency.
Compute efficiency is already all the rage as everyone wants to make AI faster, and a critical component of it is the compiler infrastructure that accelerates and connects programs to machines. That's why we're dedicating this week's blog post to deep learning compilers where we explain the current state of the space, so you can at least understand how that pile of metal manages to do your monthly job in an hour, 3 years from now!
Regular pauses make long sentences
Long-context processing is crucial for large language models (LLMs) to effectively perform many significant tasks but most LLMs are limited by a fixed context length. Although fine-tuning or retraining can increase context windows, this is generally expensive and may negatively impact the models' general capabilities when dealing with shorter contexts. Activation Beacon is a new approach that can efficiently extend an LLM's context window without compromising on shorter-context processing performance
Why would you care? Extending context can open-up new applications that current LLMs can't handle without introducing hallucinations, and Activation Beacon is presented as a plug-and-play solution to mitigate this issue efficiently. Specifically, Activation Beacon can be used to significantly extend the context context length to 100K and 400K tokens.
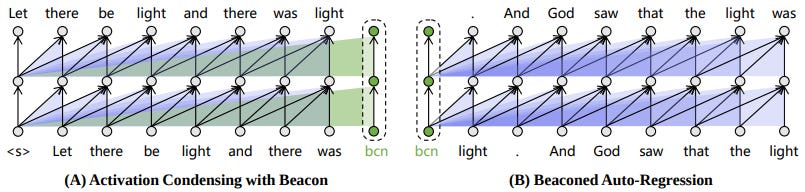
How does it work? In order to predict the next token, an LLM queries the activations within its context window. However, raw activations are costly to access memory-wise, which greatly restricts the size of the context window that can be used. Activation Beacon is based on the (empirically validated) hypothesis that raw activations contain redundant information and can thus be condensed with little overall information loss.
To compress the raw activations, Activation Beacon first divides the full context into fixed-size intervals, it then introduces a special token (beacon) at the end of each interval which condenses the activations into more compact ones. Specifically, in each decoding layer of the LLM, the beacon's input hidden states are used to transform the activation's keys and values into condensed versions, based on a pre-specified condensing factor. Further, step-wise expansion is shown to achieve optimal context expansion efficiency. This approach involves having each subsequent beacon attend to one more interval compared to its predecessor, with the last beacon attending to the entire context.
The beacons are trained auto-regressively such that the next token is predicted based on the condensed activations from previous beacons and ordinary tokens from the latest context interval. To generalise the beacon for diverse context lengths, the auto-regression needs to be conditioned on different amounts of beacons of diversified condensing ratios. For this purpose, step-wise sampling is performed at each interval such that the condensing ratio is randomly chosen from a large scope.
The design of Activation Beacon offers numerous advantages, including:
Parameter efficiency: The beacons mostly rely on the original model's parameters.
Pluggability: The beacons are trained while the LLM's parameters are fixed.
Adaptability: Both beacon and regular tokens are encoded by their relative positions within the sliding window. Therefore, the process isn't impacted by modifying the model’s position encoding scheme.
Limited overhead: Because Activation Beacon reuses other transformer modules from the LLM, beacons typically account for less than a third of the LLM’s original size.
While not available yet, the code will be open-sourced in the official repository.
The Lab
Slide-tuning Large pretrained models need to be fine-tuned on specific downstream tasks to achieve optimal performance, but end-to-end fine-tuning is typically memory-intensive. Reversible networks (that use reversible operations to allow computing inputs from outputs) have been effective in reducing memory consumption during training but because most pretrained models are non-reversible, fine-tuning reversible networks is challenging. To address this, researchers from King Abdullah University of Science and Technology and UC Berkeley propose Dr2Net to enable transitioning from a pretrained architecture to a residual architecture during fine-tuning. Instead of rewiring the original model's residual connections, new residual connections and two coefficients, α and β, are applied to the original and new residual connections, respectively. At the beginning of fine tuning, α is set to 1 and β to a small value to keep the architecture close to the original network, allowing for matched initialization. As finetuning progresses, α is gradually decreased and β increased to make the architecture resemble the reversible network, ensuring precise backpropagation. Once an acceptable gradient error level is reached, fixed α and β values are used for the remainder of the training iterations. This fine-tuning approach achieves the same precision as regular fine-tuning but requires between 25% and 50% less memory on end-to-end fine-tuning, depending on the task, facilitating the application of reversible networks for efficient fine-tuning applications.
Pinky Memory- Full fine-tuning of all LLM parameters can achieve great results but is expensive in terms of memory. Parameter-Efficient Fine-Tuning (PEFT) methods tackle this issue by fine-tuning only over a subset of critical parameters. Low-Rank Adaptation (LoRA) for e.g trains low-rank "adapter" layers to approximate updates during full fine-tuning, thereby reducing memory and computation requirements. While effective, LoRA-type methods may struggle to recover accuracy for challenging tasks with high levels of complexity. Researchers from IST Austria and Neural Magic introduce RoSA, a novel fine-tuning approach with similar computational and memory costs to LoRA-type methods but better accuracy at comparable parameter and computational budgets. RoSA revisits the low-rank assumption of the LoRA family of methods, combining low-rank adapters with sparse adapters that are trained in parallel to provide better fit, particularly for complex tasks. Results show that RoSA outperforms LoRA-based methods and is able to fully recover fine-tuning accuracy while using parameter budgets that are 40-100x smaller.
More cutting-edge research:
Knowledge Translation: A New Pathway for Model Compression The new research introduces a new framework called Knowledge Translation (KT) to address the issue of compressed models requiring re-training to recover accuracy. With knowledge translation, the parameters of a large model (or module) are taken as input and used to pre-train a “translation” model that learns to convert them into a small model (or module) while keeping the functionality approximately unchanged.
MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts This paper explores combining Mamba, a recent State Space Model (SSM) that has emerged as a strong competitor to Transformers', with Mixture-Of-Experts (MoE) that was recently used to enhance the performance of Transformer-based LLMs. In building MoE-Mamba, the authors demonstrate that this combination can be used to surpass both regular Mamba and Transformer-MoE in terms of training steps while maintaining Mamba's inference performance advantages over the Transformer architecture.
E2GAN: Efficient Training of Efficient GANs for Image-to-Image Translation Researchers from Northeastern University and Snap introduce a new approach for real-time image editing on mobile devices using data distillation that involves using large text-to-image diffusion models to create paired datasets for training generative adversarial networks (GANs). Using a combination of Low-Rank Adaptation (LoRA) to fine-tune the base GAN model's key layers and minimising the amount of data required for fine-tuning to further reduce training time, they demonstrate high-quality image editing on mobile devices with reduced training cost and storage for specialised tasks.
The Pulse
Safety conspiracy - Leading US AI companies, including OpenAI and Anthropic, have been secretly collaborating with Chinese experts to develop AI policy and address technology risks. The meetings, which took place in Geneva, were also attended by representatives from the Chinese government-backed Tsinghua University and other state-supported institutions. The goal of the discussions was to advance AI safely and establish international standards for AI safety and alignment. The talks also focused on policy proposals and have reportedly influenced discussions at the United Nations Security Council and the UK's AI summit. Future meetings are planned to further discuss scientific and technical proposals that align AI systems with legal and cultural norms.
The way it's meant to be inferred - Nvidia has announced a new set of GPUs designed for consumer-level AI applications, marking the company's expansion into the consumer AI market. The company's new RTX 40 Super graphics cards series are equipped with additional "tensor cores" specifically designed for running generative AI applications. These cards can be used for tasks such as image and video generation, language processing, and more, and are intended for use in personal computers and laptops. So far, the company's approach with regard to the local AI trend involves using a combination of cloud-based and local AI models, depending on the specific task and the need for processing power, and these new GPUs are designed to provide this balance between cloud-based and local processing.
All about that cool conductor - Transistors are becoming increasingly difficult to squeeze into smaller spaces to get more compute as they get smaller, and while most chipmakers currently stack them on top of each other, this creates overheating issues. Researchers at the Georgia Institute of Technology have found that graphene, a material excellent at giving off heat and conducting electricity but switching states to act as a transistor, can be combined with wafers made of silicon carbide to create a stable material that gives off heat 10 times better than silicon. While still not at the manufacturing stage, this discovery could potentially extend Moore's Law and lead to faster computation sooner.
Before concluding, we’d like to announce our new volunteer program!
As part of the program, contributors will get the chance to work alongside our team, get 1-on-1 mentorship, and join in with our meetings and discussions. We’ve also created a series of badges to highlight different types of contributions🛡️ and paid bounties to several open tasks 💸.
If you’d like to learn more about our new program and/or get involved yourself, then please sign up here, we’re looking forward to your contributions!
And that’s all for this edition, we hope you enjoyed reading through!
The Unify Dev Team